Swipr - Overview
The Goal
Continuing the quest to learn modern Machine Learning, I thought it would be fun to create a Tinder auto-swiper that could potentially reject matches I don’t want and accept matches I do want.
One of my friends had the brilliant idea of naming this tinderbot “Swiper”, like the fox from Dora the Explorer, famous for being repelled by the intrepid protagonists with the incantation of “Swiper, no swiping!”
Following internet tradition (Tumblr, Flickr, Scribd, Grindr, etc), we also decided to drop the final ’e’, giving us “Swipr”. And of course, our tagline is “No Swiping.”
The End Result
First, let me start up by saying that Swipr is technically available for you to use online. You can find it at https://swipr.winetech.com.
I do not recommend signing into it, and I do not recommend using it for your Tinder matches. The reasons are many, but fluctuate between security (I need to permanently store your Facebook password), practicality (both Tinder and Facebook will likely ding your account for signing in from my server’s New Jersey location), and usefulness (there is one model and it is trained on my preferences, not yours.)
But if none of those things bother you, then hey, go for it. The system is architected for multi-user support, so feel free to sign in and let Swipr do the swiping.
Process Overview
The entire process took a few weeks start to finish, and involved a number of discrete steps:
- Scope determination
- Data determination, i.e., what should I be collecting?
- Data collection
- Data cleanup
- Neural network training
- Productionizing the model
- Web app creation
- Backend architecture
And then there’s also the regular DevOps and security stuff like encrypting our databases, automating as much of our deployment as possible, and getting Let’s Encrypt certs.
Each of these steps has a bunch of nuance and complexity, some much more than others.
Model Statistics
What good is an article about AI models without some model stats? For a quick overview, here’s what we ended up getting out of the core of this whole process:
Dataset Type: a bunch of jpgs
Dataset Size: 279,262 pictures
Model Type: ResNext50
Framework: PyTorch 0.4 and fast.ai
Epoch Count: roughly 10
Total Training Time: roughly 24 hours on a Paperspace GPU instance
Loss Function: Cross Entropy
Final Loss Values:
| Training Loss | Validation Loss | Accuracy |
|---|---|---|
| 0.370794 | 0.361677 | .83086 |
Say what you want about an ~83% accuracy, but given that sometimes I’m not even sure what I want, this is a pretty solid result.
Quick Notes
Because most of you will never get past this first post, I’d like to point out some third party things that we used on this project:
For the data collection, we used a custom framework built on top of InstaLooter called ILM which handles batch downloads better.
To do data cleanup, because Instagram data is inherently noisy and not necessarily all humans, we used a prebuilt facial recognition network called DFace to find pictures with faces in them. This network is build on PyTorch. After that, we used the models available by the devs over at the DeepInsight/Face project to do gender and age analysis on the discovered faces. This model is pre-trained and built on top of MxNet.
To do Tinder work, we use Sharp-Tinder, to which we contributed a patch including .NET Core support.
Overall System Architecture
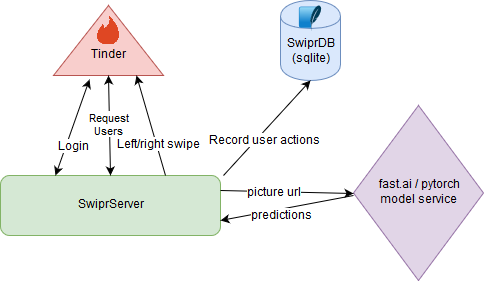
We’ll get into the details in subsequent posts, but roughly, our server calls out to Tinder to receive matches, sends pictures over to the model service to get some predictions, sends an action to tinder based on those predictions, and then updates our datastore.
Moving On
As a general rule, because each bullet from the process overview carries its own complexity, we will devote an entire post to each individual bullet.
Our next section will explore the broad project requirements.
Next Section - Outlining the Scope